Transmission et expression de l'information génétique
1 La transmission de l'information génétique
Nous avons vu dans un autre chapitre que de nombreuses cellules sont formées en permanence dans l'organisme. Celles-ci doivent maintenir leurs caractéristiques fonctionnelles intactes, et donc en l'occurrence des structures identiques. Or, ces dernières découlant de l'information génétique, on en déduit qu'il doit exister un mécanisme qui permet de dupliquer cette dernière.
1.1 L'information génétique dans la cellule
L'information génétique est portée par des structures nommées chromosomes dont le nombre contenu est le même pour une espèce donnée. On dit ainsi que le caryotype (l'ensemble des chromosomes rangés par paires, qu'il est possible de visualiser) est caractéristique d'une espèce.
Observons l'organisation cellulaire. Les chromosomes, dans les cas des cellules eucaryotes, se trouvent dans le noyau. Un chromosome est constitué principalement d'acide désoxyribonucléique (ou ADN), macromolécule en double hélice ainsi que de protéines (les histones) autour desquelles s'enroule l'ADN qui est en fait le véritable support de l'information génétique. Cette association est nommée fibre de chromatine.
Remarque : Dans une bactérie, constituée d'une cellule unique qui est délimitée par une ou plusieurs membranes et dépourvue de noyau, la molécule d'ADN est libre dans le cytoplasme.
La molécule d'ADN est formée de deux brins composés chacun d'un enchaînement de nucléotides. On appelle nucléotide la réunion d'un groupement phosphate, d'un sucre (le désoxyribose) et d'une base azotée. Ainsi, chaque nucléotide peut être identifié par sa base spécifique qui sont au nombre de quatre: adénine, cytosine, guanine et thymine. Il y a donc quatre types de nucléotides. En outre, ces bases sont complémentaires: l'adénine est associée à la thymine et la cytosine à la guanine. Il résulte de cette complémentarité que les deux brins constituant la molécule d'ADN, unis par l'existence de liaisons hydrogène, obéissent toujours à un schéma adénine/thymine, cytosine/guanine. Par exemple, la séquence ACGT d'un brin sera liée par des liaisons hydrogènes à la séquence TGCA du brin homologue. Remarquons au passage que cette structure de l'ADN que nous venons de décrire est commune aux cellules procaryotes et eucaryotes. C'est véritablement cette conformation très particulière de l'ADN qui va nous permettre de comprendre le mécanisme de la reproduction conforme.
En effet, ce que nous avons appelé information génétique jusqu'ici n'est rien d'autre qu'un enchaînement particulier de nucléotides, ou en d'autres termes de couples de bases azotées. C'est ce principe de complémentarité entre les deux brins de la molécule d'ADN qui est au coeur du phénomène.
1.2 Conservation de l'information lors du cycle cellulaire
La duplication de l'information génétique que nous avons précédemment évoquée est un processus de reproduction conforme qui donne deux cellules filles non seulement identiques entre elles mais aussi identiques à la cellule mère.
Etudions le processus. Un cycle cellulaire complet comporte deux phases : l'une d'elles, la mitose, correspond à la division cellulaire proprement dite. L'autre, nommée interphase, sépare deux mitoses.
a) L'interphase.
Avant la transmission de l'information génétique il y a toujours une réplication de l'ADN qui assure la copie conforme de l'information génétique. La double hélice d'ADN s'ouvre, les deux brins de l'ADN se séparent et vont constituer chacun un modèle pour la constitution de deux brins complémentaires : des nucléotides s'apparient à chaque brin-mère, et grâce au principe de la complémentarité des bases azotées, et sous l'action conjointe d'enzymes (les ADN polymérases) et d'énergie, deux nouveaux brins se constituent.
On obtient alors deux molécules d'ADN (qui formeront les deux chromatides de chaque chromosome) constituées chacune d'un brin-mère et d'un brin-fille complémentaire.
b) La mitose.
Celle-ci comporte quatre étapes distinctes.
- La première ou prophase, voit un changement de structure de la fibre de chromatine (ADN + histones) qui se replie alors autour d'un squelette de protéines non-histones : c'est le chromosome tel que nous sommes habitués à le voir au microscope avec sa forme en X. Il est composé de deux chromatides identiques, résultant de la condensation des molécules d'ADN, unis au niveau du centromère.
- Vient ensuite la métaphase durant laquelle les chromosomes se positionnent au centre de la cellule.
- Les deux chromatides de chaque chromosome se séparent alors et migrent chacune vers les pôles opposés de la cellule. C'est l'anaphase.
- Il y a dès lors création de deux cellules filles identiques par étranglement du cytoplasme, chacune comportant une chromatide de chaque chromosome. En dernière étape ou télophase, le matériel chromosomique de chaque cellule fille reprend la structure d'une fibre de chromatine.
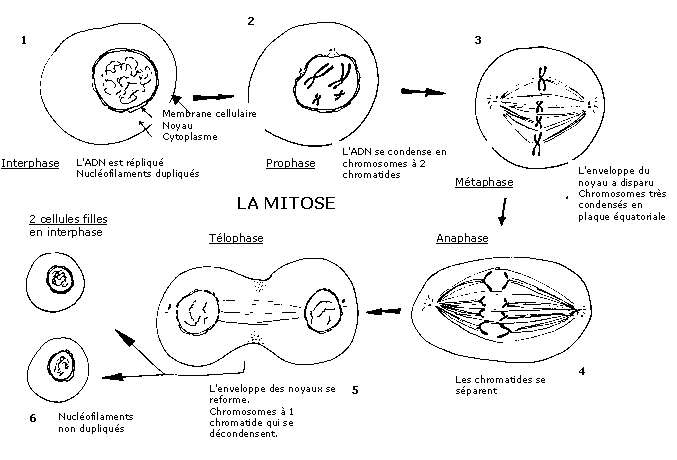
Au terme de ce processus de duplication en deux phases des cellules eucaryotes, on se retrouve finalement avec deux cellules filles ayant le même patrimoine génétique que la cellule mère: ce sont des clones.
2 La synthèse des protéines
Nous venons de voir que l'information génétique portée par l'ADN peut être dupliquée. Nous allons maintenant étudier l'expression de cette information à travers la synthèse de diverses protéines, c'est-à-dire des enchaînements variés d'acides aminés (ou chaînes polypeptidiques). L'objectif est de comprendre comment s'effectue ce processus menant du brin d'ADN à l'existence de protéines fonctionnelles.
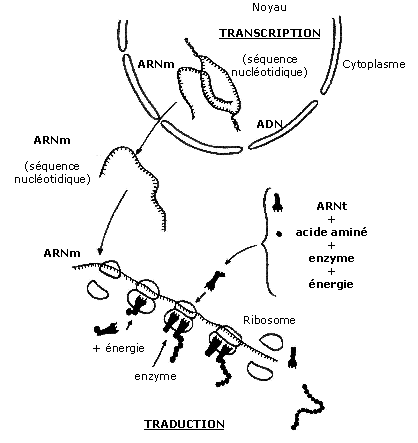
Notons tout d'abord que la synthèse des polypeptides a lieu lors de l'interphase dans le cytoplasme au niveau de structures appelées ribosomes, et est catalysée par un apport extérieur d'énergie. Or, dans le cas des cellules eucaryotes, l'ADN reste confiné dans le noyau cellulaire. Nous allons donc dégager deux phases principales dans le passage de l'ADN aux protéines: une se situant dans le noyau cellulaire que nous nommerons transcription, l'autre dans le milieu cytoplasmique appelée traduction.
2.1 La transcription
La transcription, opération qui se déroule dans le noyau des cellules eucaryotes, a pour but de synthétiser une molécule d'Acide Ribonucléique (ARN) dit messager (ou ARNm) complémentaire à un brin d'ADN donné. Celui-ci sera ensuite diffusé dans le cytoplasme: il servira en quelque sorte de transfert de l'information génétique.
Cette transcription comporte différentes phases. La double hélice d'ADN est tout d'abord ouverte sur une courte portion. Des nucléotides libres (ou ribonucléotides) présents dans le noyau viennent alors, sous l'action d'une enzyme (l'ARN polymérase), s'associer pour former une chaîne complémentaire à celle du brin d'ADN. En effet, la structure de l'ARNm est très similaire à celle de l'ADN: c'est aussi une suite de polymères de nucléotides constitués chacun d'acide phosphorique, de ribose et d'une base azotée caractéristique. Seule différence, celles-ci sont maintenant adénine, guanine, cytosine et uracile (l'uracile remplace la thymine). L'adénine s'apparie à l'uracile, la guanine s'apparie à la cytosine. Ainsi, à une séquence AGC sur le brin d'ADN correspondra la transcription UCG sur la molécule d'ARNm.
2.2 La traduction
Considérons maintenant que l'ARNm a été exporté dans le cytoplasme. Il reste désormais à passer d'une séquence de nucléotides portée par l'ARNm à une protéine, macromolécule qui n'est autre qu'une séquence complexe d'acides aminés (ou en d'autres termes une chaîne polypeptidique). C'est le processus dit de traduction dont nous allons maintenant préciser le déroulement.
Retenons tout d'abord qu'à un acide aminé précis correspond un groupe de trois nucléotides successifs portés par l'ARNm (appelé codon).
En effet, il existe 20 acides aminés différents ; avec les quatre bases (A, U, G et C), on peut former 64 combinaisons de trois bases (4x4x4). Un acide aminé donné est donc désigné par plusieurs codons ; de plus, certaines combinaisons ne désignent aucun acide aminé: on les appelle "codons stop".
La correspondance entre un codon donné et un acide aminé porte le nom de code génétique. On qualifie souvent ce dernier d'universel, de non chevauchant (dans une séquence, une base donnée ne peut pas appartenir à deux codons successifs : les codons sont lus les uns à la suite des autres sans qu'il y ait partage d'une base) et de redondant (deux codons distincts peuvent coder un même acide aminé).
Deux sortes d'ARN vont intervenir dans la traduction, en plus de l'ARNm. L'ARNr (ribosomal), d'une part, est constitutif des ribosomes. L'ARNt (ARN de transfert), d'autre part, exerce la plus grande part de la traduction.
L'ARNt possède en effet un anti-codon formé de trois nucléotides complémentaires à ceux du codon de l'ARNm. A l'intérieur d'un ribosome, L'ARNt s'apparie (grâce à son anti-codon) à un codon de l'ARNm qui lui correspond.
L'acide aminé correspondant au codon de l'ARNm que l'on veut traduire se fixe alors à cet ARNt. Peu à
peu, par reconnaissances successives, la chaîne polypeptidique s'agglomère. Dès la rencontre d'un codon
stop, le processus cesse : la protéine est formée. Elle peut alors très bien être exportée hors de la
cellule par exocytose.
Terminons notre exposé par une remarque: la transcription et traduction dans le cas des bactéries se déroulent toutes deux dans le compartiment cellulaire (puisqu'il n'y a pas de noyau) et sont simultanées.
Mots-clés :
- ADN ; fibre de chromatine ; chromatides ; chromosome.
- mitose : prophase, métaphase, anaphase, télophase ;
- interphase ; réplication
- Transcription ; ARNm
- Traduction ; ARNt ; codon ; protéine